
What is PEFT ?
Parameter-efficient fine-tuning (PEFT) is a cutting-edge technique in natural language processing (NLP) that optimizes the performance of large pre-trained language models (LLMs) while minimizing computational resources. This method allows for the adaptation of these models to specific tasks without the need for extensive retraining, making it particularly valuable in scenarios where computational power and time are limited.
Overview of PEFT
PEFT leverages the concept of transfer learning, which involves using a model trained on one task as a starting point for another related task. Instead of retraining an entire model, PEFT focuses on fine-tuning only a small subset of parameters while keeping most of the model’s original weights frozen. This approach significantly reduces the computational burden and time required for training].
Key Features of PEFT
- Resource Efficiency: By adjusting only a few parameters, PEFT minimizes the computational resources needed, allowing for quicker adaptations to new tasks.
- Prevention of Catastrophic Forgetting: Since most parameters remain unchanged, PEFT helps retain the knowledge acquired during initial training, avoiding loss of previously learned information when adapting to new tasks.
- Accessibility: PEFT democratizes access to advanced AI capabilities, enabling smaller organizations or teams with limited resources to utilize powerful models without incurring high costs associated with full retraining.
Techniques in PEFT
Several techniques fall under the umbrella of PEFT, each with its unique advantages:
- LoRA (Low-Rank Adaptation): This method represents weight updates using low-rank matrices, allowing for efficient fine-tuning with minimal memory usage.
- Prompt Tuning: This technique involves modifying input prompts to guide model behavior without altering the underlying model weights extensively.
- Adapter Layers: These are small neural network layers added to pre-trained models that can be trained on specific tasks while keeping the original model intact.
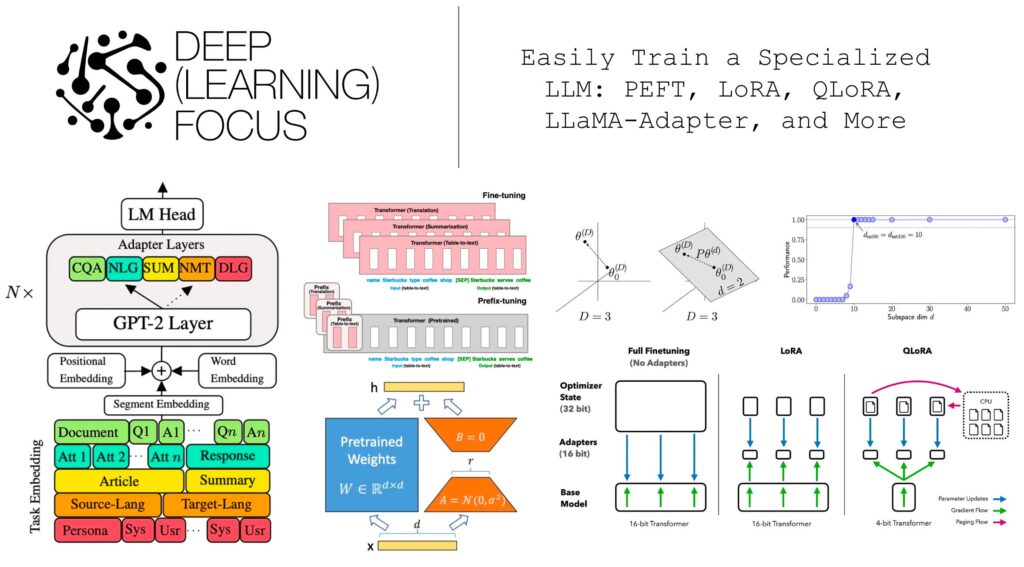
Let’s deep dive into the implementation : –
First we need to install all dependencies required .
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"- It support Llama, Mistral, Phi-3, Gemma, Yi, DeepSeek, Qwen, TinyLlama, Vicuna, Open Hermes etc
- It support 16bit LoRA or 4bit QLoRA. Both 2x faster.
max_seq_lengthcan be set to anything, since we do automatic RoPE Scaling via kaiokendev’s method.- It make Gemma-2 9b / 27b 2x faster! See our (https://colab.research.google.com/drive/1vIrqH5uYDQwsJ4-OO3DErvuv4pBgVwk4?usp=sharing)
- To finetune and auto export to Ollama, try our Ollama notebook
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = True
fourbit_models = [
"unsloth/Meta-Llama-3.1-8B-bnb-4bit",
"unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit",
"unsloth/Meta-Llama-3.1-70B-bnb-4bit",
"unsloth/Meta-Llama-3.1-405B-bnb-4bit",
"unsloth/Mistral-Small-Instruct-2409",
"unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"unsloth/Phi-3.5-mini-instruct",
"unsloth/Phi-3-medium-4k-instruct",
"unsloth/gemma-2-9b-bnb-4bit",
"unsloth/gemma-2-27b-bnb-4bit",
"unsloth/Llama-3.2-1B-bnb-4bit",
"unsloth/Llama-3.2-1B-Instruct-bnb-4bit",
"unsloth/Llama-3.2-3B-bnb-4bit",
"unsloth/Llama-3.2-3B-Instruct-bnb-4bit",
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "# UNSLOTH MODEL", # or choose "unsloth/Llama-3.2-1B-Instruct"
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)We now add LoRA adapters so we only need to update 1 to 10% of all parameters!
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
) Prepare Data
We now use the Llama-3.2(1b/3b) format for conversation style finetunes. We use Maxime Labonne’s FineTome-100k dataset in ShareGPT style. We need convert it to HuggingFace’s normal multiturn format (“role”, “content”).
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "# LLM MODEL",
)
def formatting_prompts_func(examples):
convos = examples["conversations"]
texts = [tokenizer.apply_chat_template(convo, tokenize = False, add_generation_prompt = False) for convo in convos]
return { "text" : texts, }
pass
from datasets import load_dataset
dataset = load_dataset("#use your data", split = "train")If you getting error ( while formatting data ) run these two snippet
! pip install unsloth --upgrade from unsloth.chat_templates import standardize_sharegpt
def combine_context_response(example):
context = str(example['Context']) if example['Context'] is not None else ""
response = str(example['Response']) if example['Response'] is not None else ""
return {"conversations": [{"role": "user", "content": context},
{"role": "assistant", "content": response}]}
dataset = dataset.map(combine_context_response, batched=False)
dataset = standardize_sharegpt(dataset)
dataset = dataset.map(formatting_prompts_func, batched=True) dataset[5]["conversations"]
#RUN THIS SNIPPET TO VERIFY THE DATATrain the model
Now let’s use Huggingface TRL’s SFTTrainer!
More docs here: TRL SFT docs. We do 60 steps to speed things up, but you can set num_train_epochs=1 for a full run, and turn off max_steps=None. We also support TRL’s DPOTrainer!
from trl import SFTTrainer
from transformers import TrainingArguments, DataCollatorForSeq2Seq
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
data_collator = DataCollatorForSeq2Seq(tokenizer = tokenizer),
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not is_bfloat16_supported(),
bf16 = is_bfloat16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "outputs",
report_to = "none",
),
)We also use Unsloth’s train_on_completions method to only train on the assistant outputs and ignore the loss on the user’s inputs.
from unsloth.chat_templates import train_on_responses_only
trainer = train_on_responses_only(
trainer,
instruction_part = "<|start_header_id|>user<|end_header_id|>\n\n",
response_part = "<|start_header_id|>assistant<|end_header_id|>\n\n",
) To verify weather the masking is properly done or not , run this snippet …
tokenizer.decode(trainer.train_dataset[5]["input_ids"]) 
Before training, check your cuda version and make sure nvidia driver is installed in your pc.
By typing “nvidia-smi” , you will get all your system gpu specifications.
gpu_stats = torch.cuda.get_device_properties(0)
start_gpu_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
max_memory = round(gpu_stats.total_memory / 1024 / 1024 / 1024, 3)
print(f"GPU = {gpu_stats.name}. Max memory = {max_memory} GB.")
print(f"{start_gpu_memory} GB of memory reserved.") The previous code is to check the gpu stats in your pc.
Now let’s COOK
trainer_stats = trainer.train()This code is used to check the memory usage :
used_memory = round(torch.cuda.max_memory_reserved() / 1024 / 1024 / 1024, 3)
used_memory_for_lora = round(used_memory - start_gpu_memory, 3)
used_percentage = round(used_memory /max_memory*100, 3)
lora_percentage = round(used_memory_for_lora/max_memory*100, 3)
print(f"{trainer_stats.metrics['train_runtime']} seconds used for training.")
print(f"{round(trainer_stats.metrics['train_runtime']/60, 2)} minutes used for training.")
print(f"Peak reserved memory = {used_memory} GB.")
print(f"Peak reserved memory for training = {used_memory_for_lora} GB.")
print(f"Peak reserved memory % of max memory = {used_percentage} %.")
print(f"Peak reserved memory for training % of max memory = {lora_percentage} %.") Let’s Test this recipe
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "llama-3.1",
)
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
messages = [
{"role": "user", "content": "# your prompt"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize = True,
add_generation_prompt = True, # Must add for generation
return_tensors = "pt",
).to("cuda")
outputs = model.generate(input_ids = inputs, max_new_tokens = 64, use_cache = True,
temperature = 1.5, min_p = 0.1)
tokenizer.batch_decode(outputs) After that you can save your model using several quantization methods like “q4_k_m”, “q8_0”, “q5_k_m”.
Saving will increase re-usability of your model.
⚡BAZINGA⚡
!!!! READ THIS !!!!
We successfully done this finetuning process. You will face some module error while running the snippet. Try to run the code on linux device ( Prefered ). Some modules like “triton” is highly required for this project but it is not supported in windows. Better to use wsl. If apart from this you are getting an error than connect with me on Linkedin.
The Reference is : https://arxiv.org/abs/2312.12148
ABOUT AUTHOR
 R Kiran Kumar Reddy | GDG Machine Learning Lead |
R Kiran Kumar Reddy | GDG Machine Learning Lead |
Connect on Linkedin
Follow on Github